Duplicate Instances Detection
The automatic memory analyzer will detect duplicate instances in a heap snapshot. Since duplicate instances can cause unnecessary memory usage, this information can help to better optimize the memory consumption.
Duplicate instances are detected by comparing the full instance graph of two instances. Two instances are trivial duplicates if they do not have any references to other instances, and all field values are equal. However, as soon as the instances have any reference to another instance, the full graph of reachable instances must be analyzed in order to determine whether they are duplicates.
Two instances are duplicates if each instance in the reachability graph of the first instance has a unique matching instance in the other instance graph. For an instance to match another instance, all value (non-reference) fields must be equal.
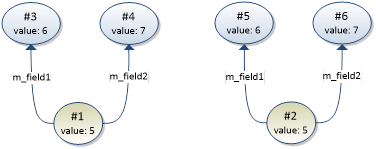
In the graph above, instance #1 and instance #2 are duplicates, since it is possible to find a unique matching instance in both instance graphs. Instance #1 corresponds to #2, #3 to #5, and #4 to #6.
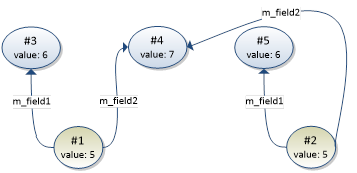
In the graph above, instance #1 and instance #2 are also duplicates. Instance #4 is reachable from both origin instances and will be matched with itself.
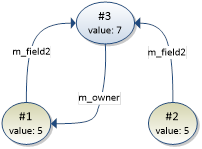
In the graph above, instance #1 is not a duplicate of instance #2, even though the instance data of instance #2 is identical to instance #1 (value is 5 and all references are equal). Instance #1 is initially matched with instance #2. However, when instance #1 is reached through the m_owner field of instance #3, it will be matched with itself (as in the previous example). Since instance #1 does not have a unique match in both graphs, the instances are not duplicates.
Duplicate Instances Additional Bytes
In order to provide a metric for how much memory duplicate instances consume, the profiler will calculate an “additional bytes” value for each set of duplicate instances.
Consider the following three duplicate instances (#1, #2, and #3):
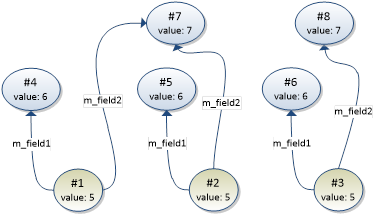
To calculate the number of additional bytes consumed by the duplicates, the profiler will merge the duplicate instance graphs into a single instance graph. Any instance not needed in the merged graph is considered an “additional” instance. In this example graph, instance #2 and #3 can be replaced with #1, instance #5 and #6 can be replaced with #4, and instance #8 can be replaced with #7 (as can be seen below).

The instances #2, #3, #5, #6, and #8 are considered additional instances, and the sum of the instance sizes will be presented as the “additional bytes” value for this set.
Held Duplicates
If a set of duplicates are found, it is often the case the duplicate instances have references to other duplicate instances. For instance, a duplicate List<> instance will have a reference to a duplicate array instance (that contains the actual list data). When investing a duplicate like this, it is usually better to focus on the duplicated List<> instance and not the array, since the duplication of the array is just a side effect.
In an attempt to identify these side effects, the profiler will provide information about duplicate sets that are fully held by another duplicate set. A set is fully held by another set if it is not possible to reach any instance in the second set without passing through an instance in the first set.
In the instance graph below, the set containing instances #4, #5, and #6 is fully held by the set containing instances #1, #2, and #3. On the other hand, the set containing instance #7 and #8 is not, since instance #8 can be reached from a root without passing through instance #1, #2, or #3.
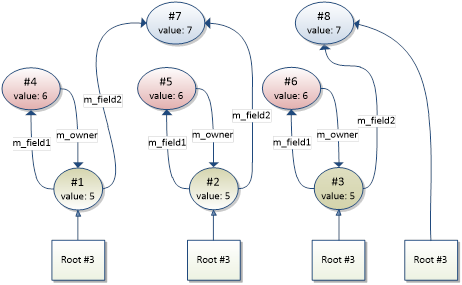
The presentation of held duplicates will contain a link to the duplicate set that is holding on to the held duplicates. This set is most likely a better candidate to investigate when trying to minimize the duplication.
Possible Duplicate Instances
To detect whether a set of instances are duplicates of each other, the profiler needs to investigate the full graph of reachable instances for each instance in the set. This investigation can take a long time for a complex memory snapshot. Therefore, the profiler will only detect trivial duplicates by default.
If a type has at least one set of instances that are not fully investigated, but can be duplicates, the profiler will add a “Possible duplicate instances” issue for this type. The “Detect duplicates” link can then be used to force the detection of all duplicates of the type.
If there are any possible duplicates in the snapshot, a “Possible duplicate instances” issue will also be added to the Overview page. The “Detect duplicates” link of this issue, and the “Profiler->Detect duplicates” command, can be used to initiate detection of all duplicate instances. However, in a complex snapshot this can take a long time.
As mentioned previously, the profiler will by default only detect trivial duplicates automatically. It is possible to change this behavior by using the Profiler->Auto-detect duplicates command. The available options are:
None
No duplicates will be detected automatically. Use the Detect duplicates links or command to initiate duplicates detection.Only trivial
Only trivial duplicates will be detected automatically. Use the Detect duplicates links or command to detect non-trivial duplicates.All
All duplicates will be detected automatically. This setting can cause the duplicates detection of the automatic memory analyzer to take a long time.